
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- django
- 개발공부
- NoSQL
- 아티클 스터디
- 파이썬
- 티스토리챌린지
- flask
- 코딩테스트
- github
- 연습
- Python
- 오블완
- Til
- web
- Wil
- 자료구조
- 도커
- SQL
- 장고
- nginx
- JWT
- Doker
- 세션(Session)
- viewsets
- 쿠키(cookie)
- git
- docker
- CS
- ERD
- redis
- Today
- Total
SteadyDrills
캐싱(Caching) 본문
241224
캐싱(Caching)이란?
캐싱(Caching)은 데이터를 임시 저장소에 저장하여 동일 데이터에 대한 반복적인 요청 시 성능을 향상하는 기술이다. 캐시는 데이터에 빠르게 접근할 수 있도록 메모리나 디스크의 일부 공간을 사용하며, 데이터베이스나 네트워크 호출 같은 느린 작업을 최소화하는 데 주로 사용된다.
예시 - 주로 정적자원(CSS,js 등), api응답, 데이터베이스 쿼리 결과 등
→ 자주 쓰는 물건을 책상 위에 올려두는 것 (정리를 안 하면 더 복잡해지지만 정리만 잘하면 효율적)
캐싱의 핵심 개념
- 임시 저장: 데이터를 원래 위치가 아닌 더 빠르고 접근성이 좋은 곳에 복사해 둔다. → 추가 저장 공간 필요, 데이터 간의 불일치 문제 발생 가능 (캐시 무효화 문제)
- 성능 향상: 원래 데이터에 접근하는 시간보다 훨씬 빠른 속도로 데이터를 가져올 수 있다.
- 반복 사용: 동일한 데이터에 대한 반복적인 요청이 있을 때 효과적이다. → 서버에 부하 감소,네트워크 트래픽을 절약
* 캐시 무효화 (Cache Invalidation)
캐싱의 중요한 과제 중 하나로 캐시 된 데이터가 최신 상태를 유지하면서, 원본 데이터 변경 시 캐시된 데이터를 업데이트를 하거나 삭제하는 과정을 말한다.
캐싱의 구성 요소

● 캐시 저장소(Cache Storage)
캐시 데이터를 실제로 저장하는 장소이다. 데이터를 빠르게 읽고 쓸 수 있게끔 보관하며, 대부분 응답속도를
위해 메모리나 저장매체를 사용한다.
- 메모리 기반 저장소:
- RAM(Random Access Memory): 빠른 읽기/쓰기 속도로 인해 주로 사용됨.
- SSD(Solid State Drive): RAM보다 느리지만 대용량 데이터를 저장하는 데 적합.
- 소프트웨어 캐시:
- Redis: 인메모리 데이터 저장소로 높은 성능을 제공.
- Memcached: 간단하고 빠른 캐싱 솔루션.
- 디스크 기반 저장소:
- 캐시 된 데이터를 디스크에 저장하여 메모리 사용량 절감. (예: 브라우저 캐싱)
● 캐시 키(Cache Key)
캐시에 저장된 데이터를 식별하는 고유한 키로 데이터를 조회하거나 갱신할 때 식별자로 사용된다.
또한 동일한 키로 동일한 데이터를 참조할 수 있도록 보장한다.
● 특성
고유성: 키는 고유해야 하며 충돌이 없어야 함.
식별성: 데이터를 명확히 구분이 가능해야 함.
● 캐시 값(Cache Value)
캐시에 저장된 실제 데이터로 키(key)를 통해 접근 가능한 데이터를 저장하며,
일반적으로 JSON, 직렬화된 객체, 문자열, 바이너리 형태로 저장된다.
● 캐시 만료(Cache Expiration)
캐시 데이터가 유효한 기간(TTL, Time To Live)을 설정하는 구성 요소이며, 오래된 데이터를 자동으로 제거하여 일관성과
효율성을 유지한다. 또한 캐시 데이터의 양을 제한하는 역할을 한다.
캐시 교체 알고리즘
LRU(Least Recently Used):
- 자주 사용되지 않는 오래된 데이터부터 제거.
LFU (Least Frequently Used):
- 사용 횟수가 가장 적은 페이지를 교체
만료 정책:
- 데이터의 특성에 따라 TTL을 설정(예: 실시간 데이터는 짧게, 정적 데이터는 길게).
● 캐시 정책(Cache Policy)
캐시에 데이터를 저장하고 조회할 때의 규칙이다. 캐시에 데이터를 삽입, 갱신, 삭제하는 방법을 정의하며,
효율적인 캐싱 전략으로 성능 최적화를 보장한다.
종류
- Write-through:
- 데이터가 캐시에 저장되면 동시에 데이터베이스에도 저장.
- 장점: 데이터 일관성 유지.
- 단점: 쓰기 속도가 느림.
- Write-back:
- 데이터가 캐시에만 저장되고, 나중에 데이터베이스에 반영.
- 장점: 빠른 쓰기 속도.
- 단점: 데이터 손실 가능성.
- Cache-aside:
- 애플리케이션이 캐시를 먼저 확인하고 없으면 데이터베이스에서 조회 후 캐시에 저장.
- 장점: 캐시에는 자주 사용되는 데이터만 저장.
- 단점: 초기 요청은 느림.
캐싱의 프로세스
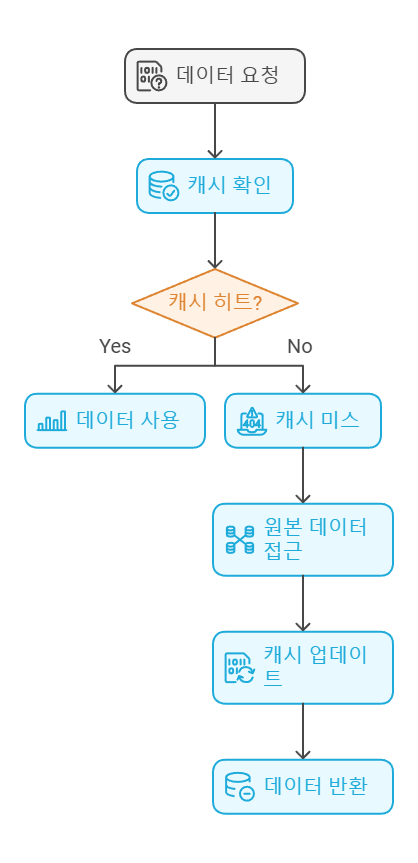
1. 데이터 요청: CPU나 프로그램이 데이터를 요청.
2. 캐시 확인: 먼저 고속 저장장치인 캐시에서 요청된 데이터를 조회.
3. 캐시 히트: 만약 요청된 데이터가 캐시에 있다면, 캐시 히트라고 하며 캐시에서 직접 데이터를 가져와 사용.
→ 캐시의 장점 성능 향상
4. 캐시 미스: 요청된 데이터가 캐시에 없는 경우, 캐시 미스.
5. 원본 데이터 접근: 캐시 미스 시 원본이 저장된 저속 저장장치(HDD 등)에서 데이터를 조회
6. 캐시 업데이트: 가져온 데이터를 캐시에 복사하여 저장. → 캐시 교체(caching replacement)
7. 데이터 반환: 요청된 데이터를 CPU나 프로그램에 제공.
'CS' 카테고리의 다른 글
| 쿠키(Cookie) (0) | 2025.01.02 |
|---|---|
| 메모리에 저장 VS 하드에 저장 (0) | 2024.12.27 |
| Docker란? (0) | 2024.12.03 |
| RDBMS와 NoSQL의 차이 (2) | 2024.12.02 |
| NoSQL (0) | 2024.11.29 |



